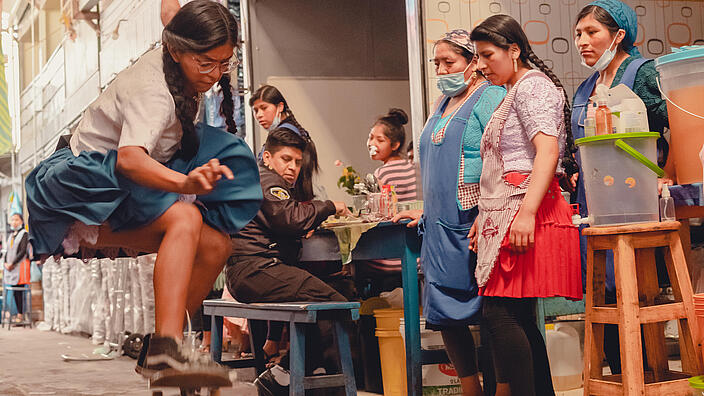KULTURAUSTAUSCH














Editor’s Picks

Jess Smee ist Redakteurin bei KULTURAUSTAUSCH. Für das Magazin hat sie sich zuletzt mit indigener Rechtsprechung, russischen Cyber-Trollen und elektronischer Musik aus Angola beschäftigt. In ihrer Freizeit schwimmt sie gerne in Seen um Berlin. Hier präsentiert sie ihre aktuellen Lieblingstexte.






Meistgelesen

Nachdenken über Literatur












Unsere Autorinnen und Autoren




















































































































































































































































































































































Das Team von KULTURAUSTAUSCH
Foto: Ole Witt
Was beschäftigt Sie?
Die Redaktion von KULTURAUSTAUSCH sitzt in Berlin, die Autorinnen und Autoren des Magazins jedoch meist ganz woanders: etwa in Lagos, Taipeh oder Bogota.
Hier können Sie direkt Kontakt mit der Redaktion aufnehmen, uns Feedback schicken oder unseren Mitwirkenden eine Nachricht zukommen lassen:
Schwerpunkte




















„KULTURAUSTAUSCH unterstützt auch jene Autor:innen, die in ihrem Heimatland kaum gesichertes Einkommen, Prestige oder Sicherheit haben. Durch dieses Netzwerk baut das Magazin weltweite Kulturbeziehungen auf“